Google News Gives Original Local Stories Credit with Local Source Tag
This article is specifically about Google News, and sites that are signed up for it. There’s only around 75,000 sites that are included in Google News. If you’re interested in getting your site entered into this section of Google, I wrote an article about that. However, even if you’re not featured in Google News, I think there are implications of what Google has done here that are applicable to SEOs in general. What Google has done speaks volumes of the direction Google is heading.
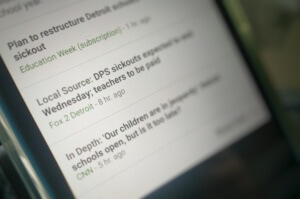
The gist is this: Google wants to give credit where credit is due. Up until now, a story has often been originated on a local level, usually by a smaller – less credible source (meaning it doesn’t have as much Domain Authority or trust as larger, mainstream news channels). Later on, however, that local news story sometimes gets picked up by the larger news outlets. In the past, once this happened, those larger news outlets would be featured in Google News – drowning out the original, smaller local original paper.
Not anymore. Now, Google is endeavoring to give credit to that local publication which originated the story. This is done with a “Local Source” Tag that is applied to the article. What is interesting about this Tag is that it’s not HTML that you stick in the source of your page. You aren’t the one that generates this tag, Google is. They apply the tag as follows:
“Local Source” articles are identified automatically by looking at where a publisher has written about in the past and comparing that to the story location.
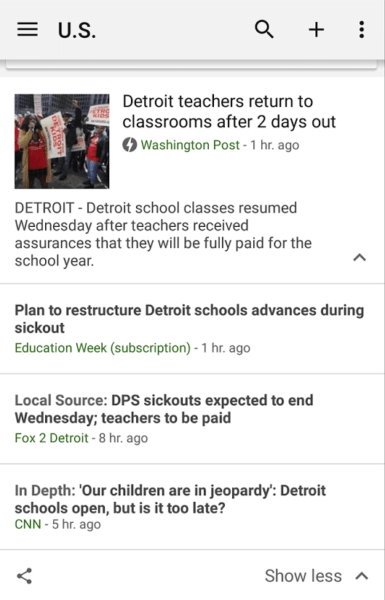 In other words, if you often write stories based on a local area, and you are the origin of the article, then you receive the “Local Source” tag and are given a rankings boost. Again, this will only affect a small subset of webmasters, but I think the direction that Google is going with this is applicable to everyone. It’s all about giving proper credit to the original article, the original source. They’re doing this even when other more credible papers later take the story up.
In other words, if you often write stories based on a local area, and you are the origin of the article, then you receive the “Local Source” tag and are given a rankings boost. Again, this will only affect a small subset of webmasters, but I think the direction that Google is going with this is applicable to everyone. It’s all about giving proper credit to the original article, the original source. They’re doing this even when other more credible papers later take the story up.
We know there are around 75,000 publishers in Google News. We have to reduce this subset even far more to come up with a group that only blogs about a specific city or location. You can imagine that this has happened because these local, original news organizations are getting shut out of their “scoops” once a story goes viral.
This is bucking a trend, and hopefully might indicate that Google will change how it has, in the past, treated websites which had their content stolen and scraped, thereafter ranking the site which stole the content higher, and reducing the ranking of the original.
Google says that if you’re being outranked by a scraper, it’s your own fault. The link referenced shows a case where a more popular site (as in it has more links) outranked another site simply by stealing the content and placing it on its own.
If a scraper is outranking your site for your original content, then something is probably wrong with your site.
In the case trial noted above, the original content apparently was penalized after the same article arrived on a more popular blog. The original site no longer ranked in the top 100 once the new location of the content on a more popular blog was indexed. Below is more information about this term.
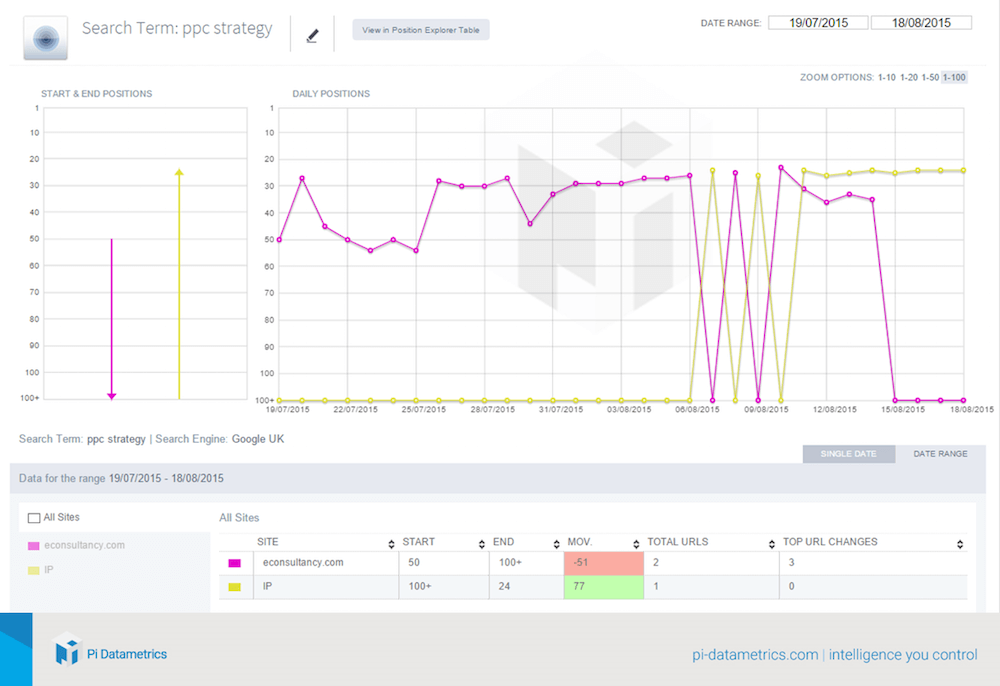
The search term that was ranking in the 20s was “ppc strategy”. It was a term that econsultancy.com used to rank for. After the content was placed on PI Datametrics’ website, you can see what happened. Over the course of six days, these sites battled it out over which would actually rank in that 20s SERP result. Afterwards, PI took over the ranking, and econsultancy.com completely dropped out of the SERPs.
Here we have two conflicting methods of which Google has treated sources of original content. With scraped content – Google has shown an apparent inability to decipher which blog actually should get credit as the original source of the article. With Google News, however (a more recent development), Google is now taking the route of giving the original source of an article more credit.
What I’m hoping is that Google is determining better strategies for deciding who should receive credit for original content. The benefits they are now giving to Google News publishers may eventually find their way to victims of content scraping. In any event, it’s showing that Google is progressing, it’s algorithms are becoming more intelligent, and ultimately this could result in more fair rankings for everyone who produces content.
 This certainly isn’t advocating stealing content. Google has protections built in to determine whether your site is off of scraped content. While you may initially get some boost if you have a credible website that is otherwise positioned well to rank, if a large majority of your content is scraped, you will certainly find your rankings plummeting quickly.
This certainly isn’t advocating stealing content. Google has protections built in to determine whether your site is off of scraped content. While you may initially get some boost if you have a credible website that is otherwise positioned well to rank, if a large majority of your content is scraped, you will certainly find your rankings plummeting quickly.
In general, duplicate content on your site will harm your rankings. All of the internal links you have that point to that page, that link juice will be nulled and wasted. When your site mainly consists of duplicate content, it is bad for your rankings. The study given above where it was beneficial for rankings to steal content featured a site that otherwise had great things going for it, a high level of credibility and links, and the small amount of duplicate content featured made that content rank. If that method was the bulk of their tactics (scraping), ultimately their rankings would suffer.

Comments