Building Sites with Abandoned Content
I’m going to describe a powerful method to get content. This probably isn’t the first time using this method has been discussed, however, I believe I have some twists that make the method far more powerful. Right here, right now, archive.org has hundreds of thousands of pages of good, well written, unique content that isn’t available anywhere else on the internet, and Google doesn’t know about that content.
![]() This concept isn’t new. Building websites based on articles found in archive.org is an idea that has been around. The trick, however, can be in finding that content. There is simply no practical way to search historic web pages in archive.org’s index. An analogy of this is searching for a needle in a haystack, and needing to know where good content used to be found, in order to revive it on your site.
This concept isn’t new. Building websites based on articles found in archive.org is an idea that has been around. The trick, however, can be in finding that content. There is simply no practical way to search historic web pages in archive.org’s index. An analogy of this is searching for a needle in a haystack, and needing to know where good content used to be found, in order to revive it on your site.
Before I show you how to find content fairly easily, lets talk about whether or not you should use content that someone else wrote. To a certain degree, the person who wrote that content, owns it. My own feeling in regards to this is that they abandoned it, because they let their website expire, and that using it is fine. That, of course, isn’t legal advice — if you’re that concerned about it, however, there’s other things you could do and still take advantage of this idea.
If you’re very concerned about using this type of content on your own personal website, you can consider using the content to build your personal blog network, or putting the content on free web2.0 blogs, with links back to your money site. That puts a degree of separation between you and the content. Again, I think that’s going overboard — if someone is lazy enough about protecting their content that they let their domain expire, then chances of them hunting you down after you use their long-expired content is virtually none.
Here are my tricks and tips to finding this expired, abandoned content. Begin to imagine domain names that should have decent content for your niche. I’ll give an example of weight loss. I sat down to think of several types of domain names that could possibly reflect the weight loss niche, and on the fifth try I came up with this domain: https://web.archive.org/web/*/http://www.howtoloseweightfast.com/. Incidentally, notice how that URL is formulated. By switching the domain at the end, you can quickly browse hundreds of domains.
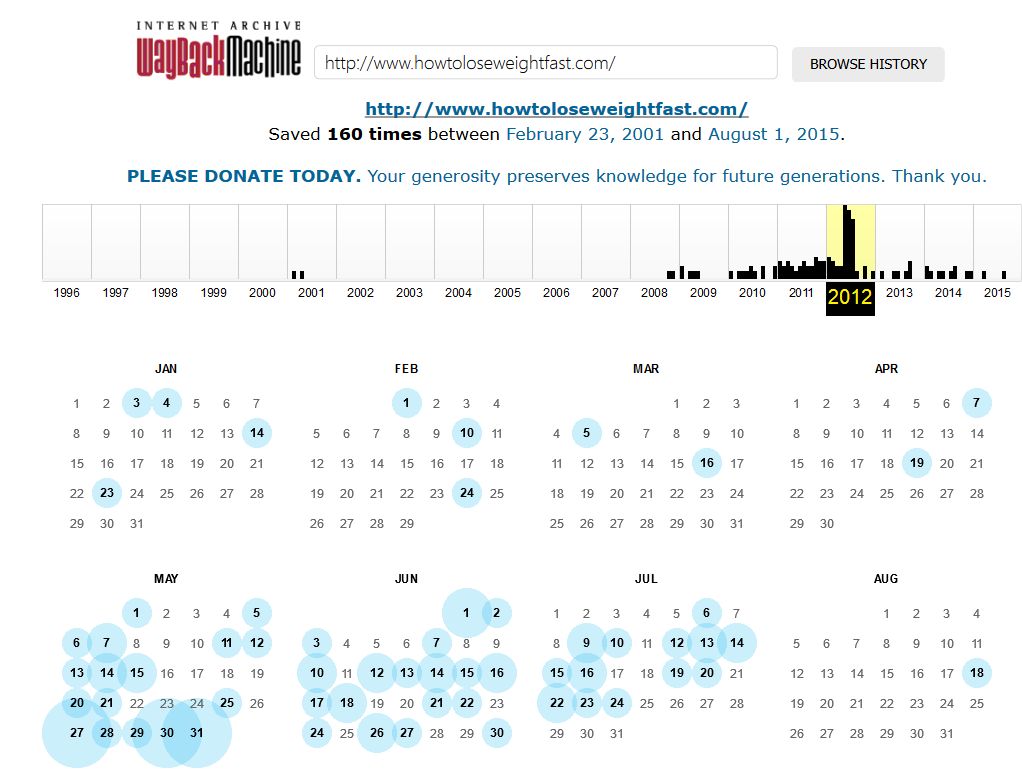
You can tell at a glance, because of how many black slashes there are within that domain’s timeline, that it has had a lot of content over the years. I noticed a significant spike in content creation and spidering in the year 2012. I visited that page, and clicked on May 30th, simply because that had a huge circle indicating many content updates. At a glance, I could tell that this is a site with few pages, but some longer articles. That’s exactly what we’re looking for!
The homepage has a healthy dose of content on it. What we will do now is take blocks of text, and search Google for these blocks to make sure that the content is unique, and no longer indexed in Google. I took a random sentence, under the 3rd point, “There is no need to push yourself like a tri-athlete to see the benefits”. Searching for this on Google, I notice that text is in Google 44 times. Darn. Well, even though that article is already indexed, it doesn’t mean they all are. So, I check the other articles on the site.
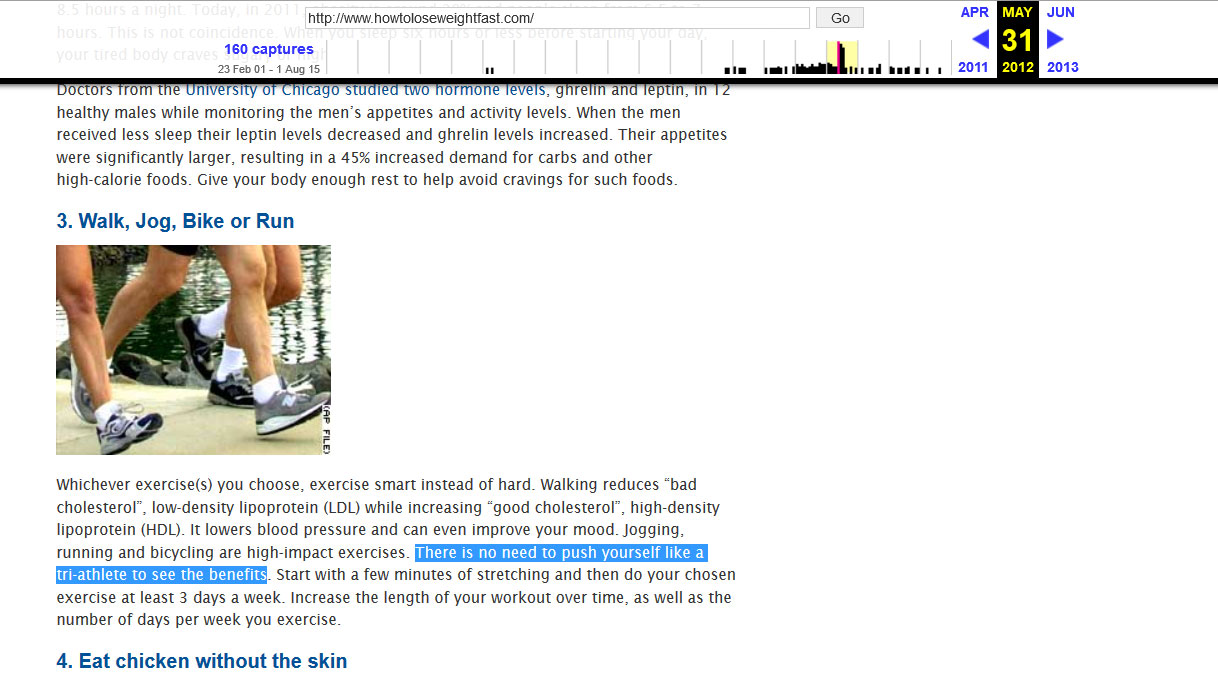
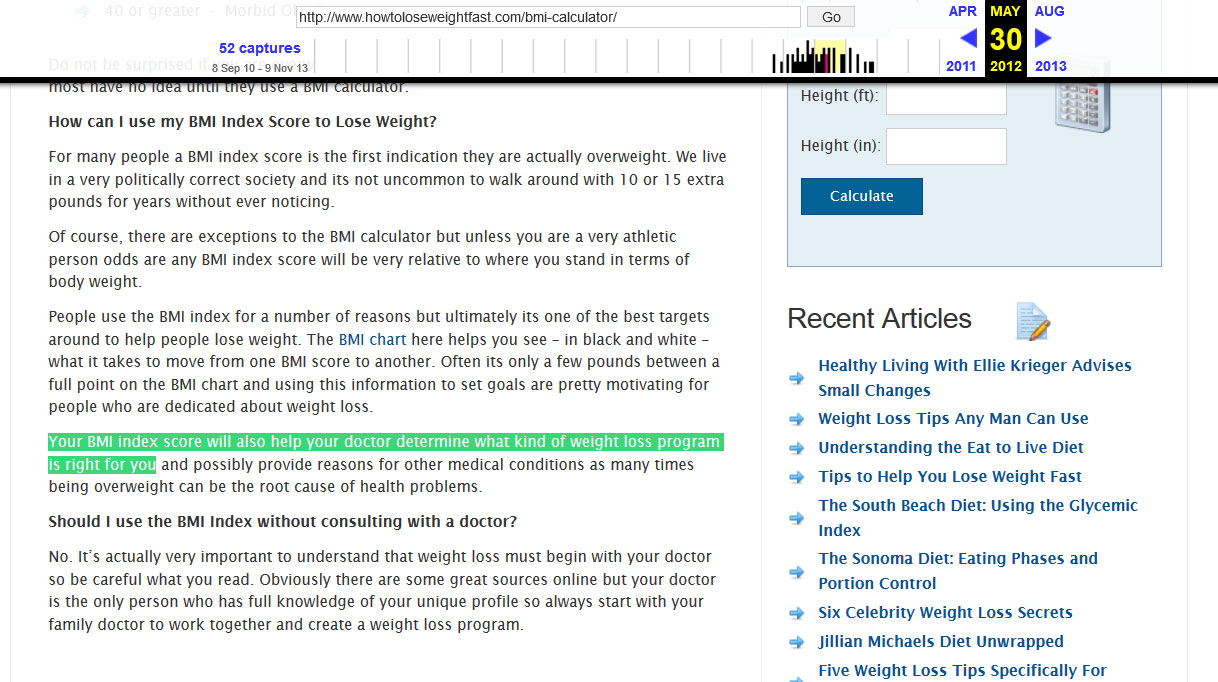
The first link on the top is to their BMI calculator page, so I click it. At 499 words, it’s a fair length article. I grab a few blocks of text and check it in Google. “Your BMI index score will also help your doctor determine what kind of weight loss program is right for you.” I search Google. Nothing. Bingo! In less than two minutes of messing around, I discovered a 499 word article about weight loss that isn’t in Google.
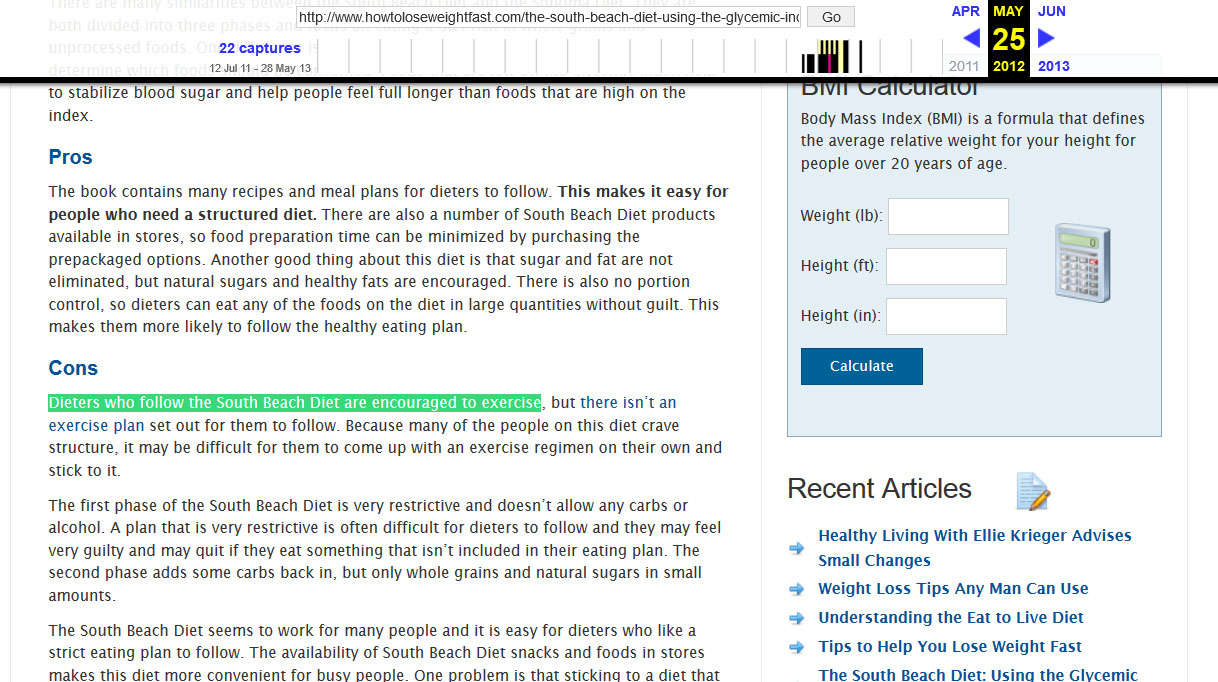
Next, under the “Recent Articles” list, I see an article entitled, “The South Beach Diet: Using the Glycemic Index”. I then scroll down and grab a chunk of text, “Dieters who follow the South Beach Diet are encouraged to exercise” and search Google with it. Nothing. Bingo! As it turns out, I’ve discovered an entire built website, where nearly all the articles are unique. That particular article was 451 words. The content is a little on the light side, if I were going to use this site’s content, I would probably take 2 articles and combine them into one to make 800+ word articles out of it.
By guessing domain names that should have had decent articles in the past, you can easily find dozens, hundreds, even thousands of unique articles. While the content on this site is a little on the light side — I may have just taken it all and uploaded it to a web2.0, and made a highly unique tier-1 blog out of it, or put the content on one of those 99 cent .xyz domains that came out this year. I’ve used this technique to build entire money sites from in the past. You could very well hit the jackpot, and find yourself sitting on a 50+ money site with excellent content using this technique. At the very least, it makes excellent fodder for your personal blog network, or your tier-1 free blog sites.
This concept works best when dealing with an informational niche. Losing weight works great, because the articles would be evergreen. It is a niche where writers try to teach you how to do something. You’ll have good success finding excellent content on domains that begin with “howto”, because that implies the site has articles that will teach something.
 This is a great way to make money with SEO for those who may not have English as a native language. It helps finding articles that are already well written. Imagine how much money you can save from outsourcing content, by building your money sites, personal blog network and free blogs through this technique, instead of hiring out all the content creation.
This is a great way to make money with SEO for those who may not have English as a native language. It helps finding articles that are already well written. Imagine how much money you can save from outsourcing content, by building your money sites, personal blog network and free blogs through this technique, instead of hiring out all the content creation.

Comments