Google Detecting Hidden Content Resulting in Filter Penalties
Contents
A patent was issued in 2013 to Google’s very own Matt Cutts, in regards to methods used to discover hidden content, and hidden links. While many of you may be thinking “This doesn’t affect me, I don’t hide text or links!”, the problem is that many templates and themes for WordPress and other CMS systems have built-in functionality for hiding content.
If you’re using short-codes to expose content when clicking on a tab, or using shades and variants of background colors and font colors that are extremely similar, using extremely small fonts, or even linking to JavaScript files that Google can’t fetch — you are sending a negative signal to Google, that you may be trying to hide content. SEO is about providing positive signals, and avoiding negative signals — otherwise, your site will be filtered from the SERPs if the negative signals outweigh the positive.
Of course, Google wants what you show to Google to exactly match what the end user’s experience to be when they visit your page. If you are hiding text and content, or hiding links — Google would consider this as manipulating your rankings, by providing stuffed data that isn’t actually available on your page. If someone finds your page, based on content that is supposedly there, yet that content is hidden when they arrive on the page, that can provide a negative user experience. As such, Google would reduce your rankings based on the perceived manipulation.
Following are the things this patent claims that Google can detect, starting with Javascript and CSS hiding of content.
Javascript and CSS hiding of content.
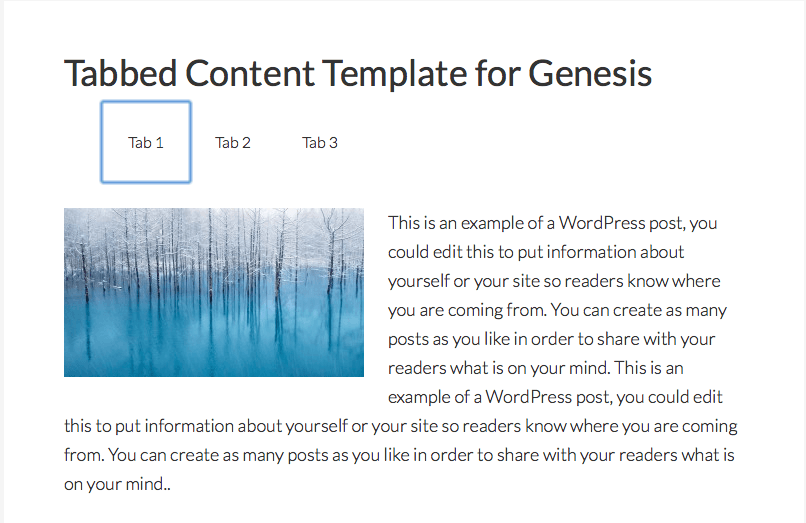 I’m listing this one first, because it is something that many SEOs violate unwittingly. An extremely common tactic that many templates use is a “tabbing” structure, where there are several tabs displayed. Each tab has a block of content behind it, that is hidden until the tab is clicked, exposing the content. While this can be a helpful method to paginate content into more easily assimilated smaller chunks of text, it is a method that is used by webspammers to stuff a page full of content in the hopes of ranking higher.
I’m listing this one first, because it is something that many SEOs violate unwittingly. An extremely common tactic that many templates use is a “tabbing” structure, where there are several tabs displayed. Each tab has a block of content behind it, that is hidden until the tab is clicked, exposing the content. While this can be a helpful method to paginate content into more easily assimilated smaller chunks of text, it is a method that is used by webspammers to stuff a page full of content in the hopes of ranking higher.
Another case of hidden content is drop-down menus. The way these work, sub-menu areas are hidden until a mouse is hovered over an area to drop that menu down, and expose those sub sections. The problem is, that menu is completely hidden by JavaScript and CSS before being exposed, and this can trip a filter penalty based on the belief you’re hiding content on your page.
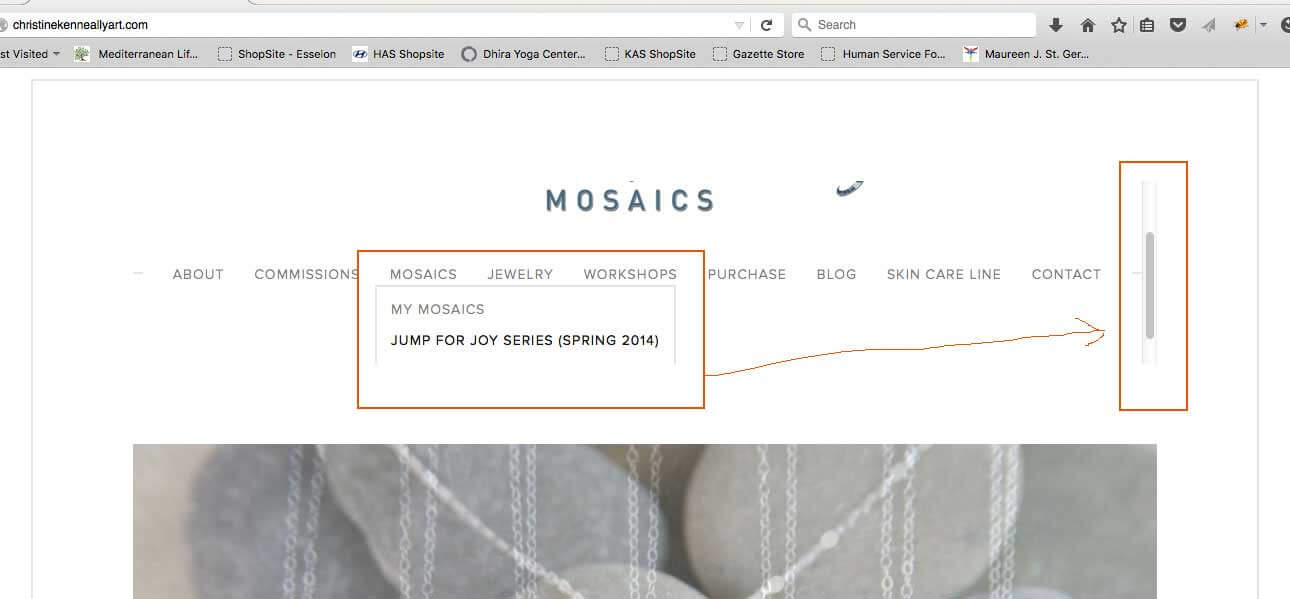
Google cannot tell the difference,
whether your intention of hiding the content is to benefit a user or not. Using this sort of tabbed content sends a negative signal to Google. Certainly, the page can rank if it has enough positive signals — but it is best if you avoid all possible negative signals you can. Following are some wordings found in Matt Cutt’s patent:
JavaScript is used to dynamically change the content of a document, server 120 may monitor the tree-like structure associated with the document for changes. If more than a predetermined amount of text is added to (or deleted from) the document, the document may be further analyzed to determine if the document is being used to trick a search engine into ranking the document more highly.
Above we have Google examining what they can see, also examining what a user can see after chunks of text are hidden, and comparing each. If a “predetermined amount of text” is deemed to be hidden by JavaScript, then Google perceives it as “being used to trick a search engine”. We don’t know what the size of the predetermined amount is, whether its a few words or a paragraph-sized chunk of text. It is best not to hide any text using JavaScript or CSS.
To avoid these problems — I recommend no hiding of text whatsoever. Do not use hidden drop-down menus that are exposed when hovering your mouse over a section. Also, do not use any tabbed areas, where content is hidden until a tab is clicked, thereafter exposing that hidden area. Lastly, of course, don’t use JavaScript and CSS to intentionally hide text on a page in hopes of ranking for terms that normal visitors cannot see — the end result is a negative signal being registered by your actions.
Make sure Google has access to your CSS and JS files.
Google examines your .css and .js files to make certain text is not being hidden. If you inadvertently block Google from accessing these resources, by placing them in a directory where Google is prohibited from visiting via the robots.txt file, Google would then not be able to render how your page looks. This would be bad from the perspective of Google not knowing whether you’re trying to hide text, but furthermore — it wouldn’t know if your page is compliant for mobile traffic. Making .js and .css files inaccessible is not recommended, and make sure your robots file isn’t blocking the /wp-content/ directory (where many .css and .js files are located), because that is where your WordPress theme is typically found.
Hiding links.
 Another part of the patent involves links that are virtually hidden by the fact that the anchor text is so small. For instance, if a link is fashioned as such: <a href=”http://example.com/”>.</a>, Google would determine that link is being hidden. The patent also mentions a dash being used, and one could also assume that a 1 pixel image would also trip their filter.
Another part of the patent involves links that are virtually hidden by the fact that the anchor text is so small. For instance, if a link is fashioned as such: <a href=”http://example.com/”>.</a>, Google would determine that link is being hidden. The patent also mentions a dash being used, and one could also assume that a 1 pixel image would also trip their filter.
Another method of link hiding involves using images that are the same color as the background. The patent states:
One technique for hiding links involves the use of a very small image (e.g., a 1.times.1 pixel graphic interchange format (GIF)) that is used as a hyperlink. The image can be made to be so small that the image is not visible to users viewing the document, but may still be considered by search engines when ranking documents. In other situations, large images (e.g., 300 pixels wide and 200 pixels high) that are hyperlinks may be used that are the same color or similar color to the background.
To avoid having a problem with this portion of Google’s filter, make all your links obvious. The text in them should be of sufficient length, and if linking with an image, the image color and background color should not be the same.
Image processing compared to document layout.
I found this next part amazing — that Google would go through such extents to try to find hidden text. This is what Google is capable of:
As an example, assume that a document has a blue background, a white background image placed on the blue background, and white text written in a table having a transparent background that that is placed on the background image.
That blockquoted section continues, explaining how Google will know that if you have a blue background, and a section of your layout has a white image set as the background of a div, and that div has white text, Google can detect it. I find it amazing that they process documents to that high of a degree.
Cloak detection.
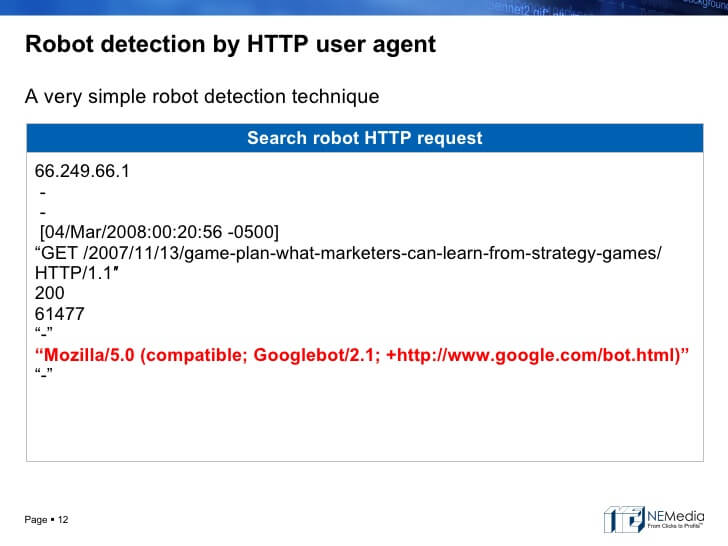
Can Google determine whether you’re cloaking? Some sophisticated cloakers use various methods beyond simply looking for “Googlebot” as a user agent, going so far as to record all the IP addresses Google is known to visit through. Following is a portion of the patent pertaining to this.
FIG. 1 is an exemplary diagram of a system 100 in which systems and methods consistent with the principles of the invention may be implemented. System 100 may include multiple clients 110 connected to servers 120 and 130 via a network 140. Network 140 may include a local area network (LAN), a wide area network (WAN), a telephone network, such as the Public Switched Telephone Network (PSTN), an intranet, the Internet, a similar or dissimilar network, or a combination of networks. Two clients 110 and three servers 120/130 have been illustrated as connected to network 140 in FIG. 1 for simplicity. In practice, there may be more or fewer clients 110 and/or servers 120/130. Also, in some instances, a client 110 may perform the functions of a server 120/130 and a server 120/130 may perform the functions of a client 110.
Clients 110 may include devices, such as wireless telephones, personal computers, personal digital assistants (PDAs), lap tops, etc., threads or processes running on these devices, and/or objects executable by these devices. Servers 120/130 may include server devices, threads, and/or objects that operate upon, search, or maintain documents in a manner consistent with the principles of the invention. Clients 110 and servers 120/130 may connect to network 140 via wired, wireless, or optical connections.
Google’s hidden text and cloaking patent involves reading of web pages through a variety of networks, and through a variety of devices, in order to test whether you’re serving the same types of content to all of them.
In summary, everyone should verify that their templates do not hide content via menu or tabs. This is the one that potentially affects everyone. If you are someone who considers various blackhat methods to stuff text into a document, via content hidden through .js/.css or through cloaking, Google has infrastructure in place to detect it. These are negative signals. They may, or may not affect your rankings depending on whether your site has other positive or negative signals going on, which would either protect you from, or exacerbate penalties for various forms of hidden text on your pages.

Comments