Pages Indexed on Free Blogs Are Dropping – What It Means To You
There is a trend with Google that, when you step back and consider it, you realize the future of where SEO is headed. I’m talking about “pages indexed”. Google is literally dumping pages from it’s index at an ever-growing rate. This says a lot about the future of blackhat link building techniques. There are reasons for this, which I’ll explain in a bit, but in general the future of SEO is more about quality, and less about quantity. 
The theory is that if you have a link from a page that isn’t indexed, that link doesn’t count. There are huge services built around that theory. Companies such as Lindexed, Linklicious and others, provide a service that essentially says, “Hey Google! You don’t like these junky sites linking to our collective money sites? Well we don’t care, we’re going to keep pinging them, or spamming links to them and tell you about them until you do!” These services will take low quality profile links, spam comments, spun wiki webspam and web2.0 free blogs, and keep ramming them down Google’s throat until every single one is in Google’s index.

Just for the heck of it, because I’m a weird or something — I just so happen to keep track of how many pages free blogs keep indexed over time. At one time, Blogger had over a billion pages indexed. This is where you type site:blogspot.com and see how many pages they show as part of their index. One year ago today, they were reduced to 797 million. Six months ago, 382 million. Today — 230 million. Over the last year and a half,Blogger dumped over 75% of all the pages they have indexed. 3/4ths of those pages are nuked into oblivion, Google no longer cares enough about them to keep them indexed. In a few moments, I’ll explain what is happening to these pages, but first let’s talk about the ramifications of what this means.
![]() Google is dumping Blogger blogs. Those blogs no doubt still exist, but they’re not indexed. Here we were talking about these indexing services trying to shove pages down Google’s throat, to get them indexed — meanwhile, Google is throwing out 3 of every 4 pages on its own blogging platform. Google isn’t the only one, last year WordPress had 341 million pages indexed. Six months ago, 192 million. Today: 150 million. Tumblr dropped from 191 million a year ago, to 82 million today. I have similar stats on over 50 free blog platforms, with the volume of pages indexed declining at similar paces amongst all of them.
Google is dumping Blogger blogs. Those blogs no doubt still exist, but they’re not indexed. Here we were talking about these indexing services trying to shove pages down Google’s throat, to get them indexed — meanwhile, Google is throwing out 3 of every 4 pages on its own blogging platform. Google isn’t the only one, last year WordPress had 341 million pages indexed. Six months ago, 192 million. Today: 150 million. Tumblr dropped from 191 million a year ago, to 82 million today. I have similar stats on over 50 free blog platforms, with the volume of pages indexed declining at similar paces amongst all of them.
The future of SEO is in having links from diverse (not simply unique) pieces of relevant content. All the difficulty in having pages indexed, and pages being dropped from Google, is merely the symptom of a deeper underlying issue. That underlying issue is this — Google understands what unique, diverse content is — compared to redundant content. Notice I’m not talking about what passes copyscape — passing copyscape is child’s play compared to Google’s latest diversity filters. In a few moments I’ll comment on some of Google’s patents, which purports they have the ability to eliminate redundant information from the SERPs, but before I do let’s make the connection and put it all together.
Where are the pages indexed going? Why, on some sites, do you see your indexed rate skyrocket when typing site:example.com on a new domain of yours, only to find that later on many of those pages disappear? The reason the pages won’t stay indexed is they’re not diverse enough. They’re considered redundant. They bring no new information regarding a particular topic, and as such they’re dumped from the index.
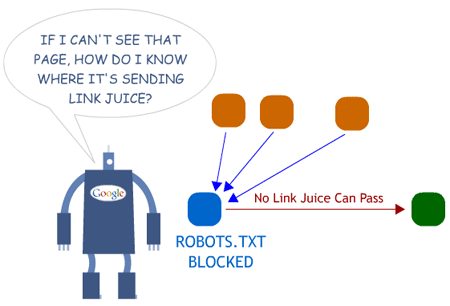 When you consider that you can take someone’s article, rewrite it so that it makes all the same points (but uses different words) and stick it on a site — and that page will get deindexed, it’s no wonder that so many pages are dropping from free hosts. That rewritten content is worthless. Google won’t keep it indexed. If it’s on your site, you’re showing Google that your site has redundant information, which isn’t good for your ranking prospects across your entire site. If you built that page as a part of a private blog network, with a link pointing to your own site — that page’s link is considered worthless if it winds up being thrown out by Google’s diversity filter.
When you consider that you can take someone’s article, rewrite it so that it makes all the same points (but uses different words) and stick it on a site — and that page will get deindexed, it’s no wonder that so many pages are dropping from free hosts. That rewritten content is worthless. Google won’t keep it indexed. If it’s on your site, you’re showing Google that your site has redundant information, which isn’t good for your ranking prospects across your entire site. If you built that page as a part of a private blog network, with a link pointing to your own site — that page’s link is considered worthless if it winds up being thrown out by Google’s diversity filter.
If you’re building blog networks for the purpose of getting links, and they’re not working — you need to keep reading. One of the main reasons your blog network may be failing is because the content on them is redundant. Google has patents that specifically mention finding a page that is redundant, and discounting its outgoing links. Next, we’ll discuss Google’s patent, and afterwards what you can do about it.
I’ve written a page that completely covers all aspects of this particular patent — however, for the purposes of this article I’ll just cover the diversity filter, how it discards pages as well as their links. The patent wording is here. Particularly, we’re concerned with this excerpt:
To determine the link quality score, the link engine can perform diversity filtering on the resources. Diversity filtering is a process for discarding resources that provide essentially redundant information to the link quality engine.
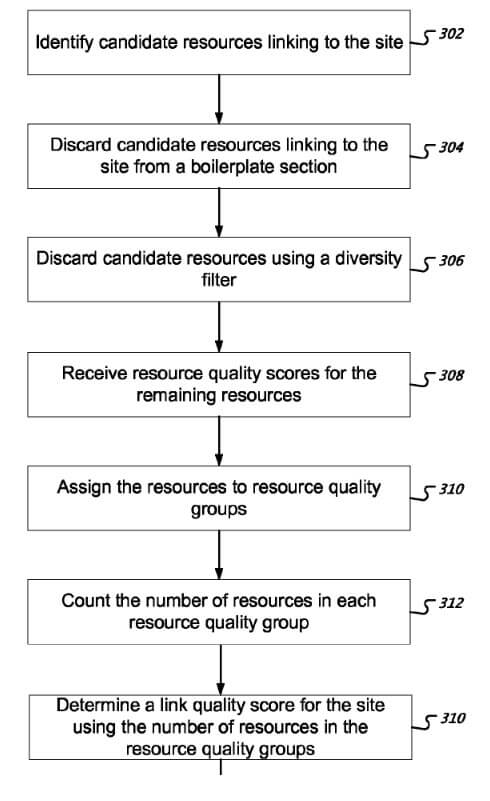 In context, the above content is talking about the value of links to your site. That value is the “link quality score”. The pages you get links from are the “resources”. Google has a diversity filter which discards “resources” (the pages you get links from), if those resources provide “essentially redundant” info.
In context, the above content is talking about the value of links to your site. That value is the “link quality score”. The pages you get links from are the “resources”. Google has a diversity filter which discards “resources” (the pages you get links from), if those resources provide “essentially redundant” info.
In layman’s terms, that article spin that you pushed to your 50 blog network — Google knows they’re the same article. All the links are worthless. This is a negative signal, and if you have other negative signals combined with it, Google is likely to penalize your site heavily.
The following is another excerpt from the patent, which is of concern to anyone who builds links to their own money site:
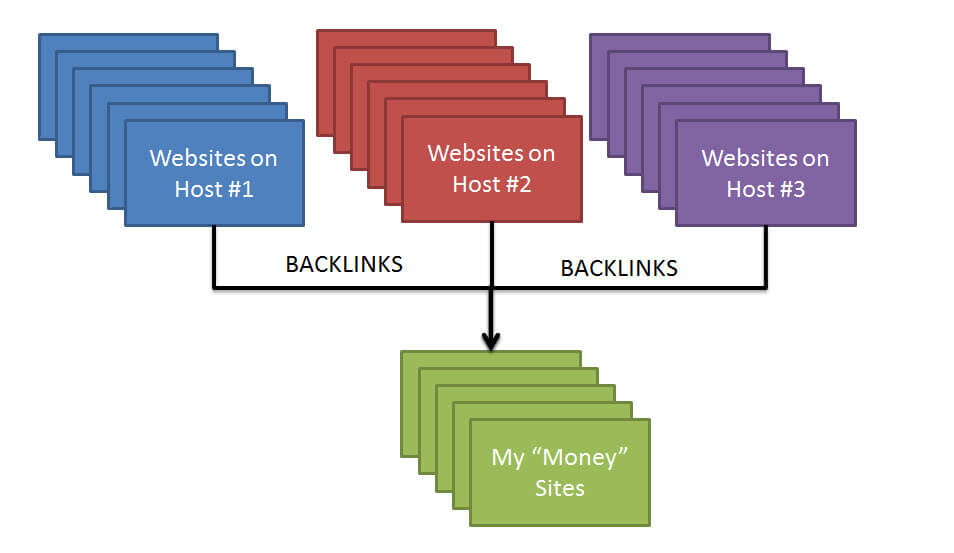
For example, the system can determine that a group of candidate resources all belong to a same different site, e.g., by determining that the group of candidate resources are associated with the same domain name or the same Internet Protocol (IP) address, or that each of the candidate resources in the group links to a minimum number of the same sites. In another example, the system can determine that a group of candidate resources share a same content context. A content context is a characterization of the content of a resource, e.g., a topic discussed in the resource or a machine classification of the resource.
Here, we see Google talks about “candidate resources” that are “associated with the same domain”. Those resources are pages that link to you. Google made a determination that those pages are “associated” with you, or in other words, you made them yourself. Google makes this determination in various ways. One is by IP address. I think we can all imagine Google figuring out you’re responsible for links if they’re all coming from the same IP address.
 Another method is that they “share a same content context”. Another way they phrase this as is “a characterization of the content”. In other words, if there is a free blog on the left, which has 5 pages regarding your topic — all centered around the same keywords, and on the right there’s a hosted domain that is also 5 pages of content organized in the same fashion, making the same points — this means you made those pages with those links, and they’re discounted. A negative signal has been issued, and when combined with other negative signals — you’ll see your rankings drop.
Another method is that they “share a same content context”. Another way they phrase this as is “a characterization of the content”. In other words, if there is a free blog on the left, which has 5 pages regarding your topic — all centered around the same keywords, and on the right there’s a hosted domain that is also 5 pages of content organized in the same fashion, making the same points — this means you made those pages with those links, and they’re discounted. A negative signal has been issued, and when combined with other negative signals — you’ll see your rankings drop.
This is a big deal, and not many people are talking about it. You can find an article from Bill Slawski, who is excellent at keeping up with Google’s patents. Whitehat sites don’t discuss it — because whitehat sites take the view that you shouldn’t simply be rewriting other people’s content in order to rank in the first place, and certainly not using article spins.
Blackhat sites aren’t talking about it — which is a shame, because one of the best tactics for building rankings today involves building your own private blog network, and yet you see sites like Nohat Digital, (who used to build PBNs and recommended doing so) giving up on PBNs and building links using other more whitehat techniques. Don’t get me wrong, I’m not knocking taking a whitehat route to building links — but knowledge is power. Whitehat can be a better ROI, especially if doing a private blog network wrong. For me, it has nothing to do with the supposed moral or ethical reasons behind how we build links, all I care about is “What works?”, “Is it scalable?” and “What are the risks involved?”
 Every SEO should realize that getting links from similar pages, that have similar content constructions, that aren’t diverse — will culminate in those pages being discarded from Google, the links not counting and a negative signal being registered. While whitehats promote this as a moral and ethical “thou shalt not” method — it all boils down to Google’s algorithm, what they can sense and detect. Blackhats should be cautious when building content (for linking purposes, or for their money site) which isn’t sufficiently diverse — not because it’s “wrong”, but because Google can detect it.
Every SEO should realize that getting links from similar pages, that have similar content constructions, that aren’t diverse — will culminate in those pages being discarded from Google, the links not counting and a negative signal being registered. While whitehats promote this as a moral and ethical “thou shalt not” method — it all boils down to Google’s algorithm, what they can sense and detect. Blackhats should be cautious when building content (for linking purposes, or for their money site) which isn’t sufficiently diverse — not because it’s “wrong”, but because Google can detect it.
The future of SEO isn’t going to be shoving bad content down Google’s throat using indexing services. Instead, it will be through building diverse content that Google indexes. It isn’t hard to get diverse content indexed. This negates a large number of link methods that are purchased, generated from blackhat software. The trend of low quality links hurting, more than helping, will continue.
This isn’t to put down private blog networks, or free blog networks. The sin isn’t in building them, its in having them built wrong. Content diversity is a prerequisite to building a powerful private blog network.

Comments